Research
How can AI systems understand and interact with humans in a natural and intuitive way?
This fundamental question drives my research in Human-Centric AI, where I focus on developing
intelligent systems that can perceive, understand, and generate human-centered content across multiple modalities.
Specifically, I am investigating Human-Centric generation methods that can create realistic human avatars,
videos, motions, and behaviors, as well as multimodal perception tasks that enable AI systems to understand
human activities, emotions, and intentions from diverse sensory inputs including vision, audio, and text.
Equal Contribution *, Corresponding Author †, Project Lead ⚑
Your browser does not support the video tag.
UP2You: Fast Reconstruction of Yourself from Unconstrained Photo Collections
Zeyu Cai ,
Ziyang Li ,
Xiaoben Li ,
Boqian Li ,
Zeyu Wang ,
Zhenyu Zhang† ,
Yuliang Xiu†
project page /
arXiv /
code
Reconstruct 3D avatar from unconstrained photo collections.
Your browser does not support the video tag.
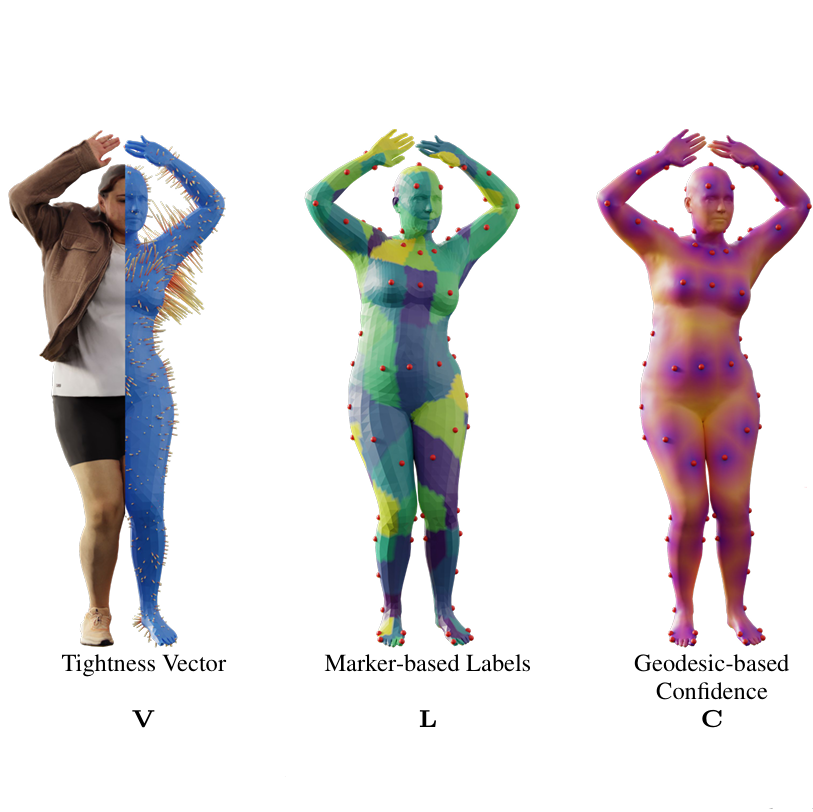
ETCH: Generalizing Body Fitting to Clothed Humans via Equivariant Tightness
Boqian Li ,
Haiwen Feng⚑ ,
Zeyu Cai ,
Michael J. Black ,
Yuliang Xiu†
ICCV ), Highlight , 2025
project page /
arXiv /
code
Clothed human scan body fitting using equivariant tightness.
Your browser does not support the video tag.
StrandHead: Text to Hair-Disentangled 3D Head Avatars Using Human-Centric Priors
Xiaokun Sun ,
Zeyu Cai ,
Ying Tai ,
Jian Yang ,
Zhenyu Zhang†
ICCV ), 2025
project page /
arXiv
SDS-based text-to-3D head avatars with hair strand.
AssetDropper: Asset Extraction via Diffusion Models with Reward-Driven Optimization
Lanjiong Li* ,
Guanhua Zhao* ,
Lingting Zhu*⚑ ,
Zeyu Cai ,
Lequan Yu ,
Jian Zhang ,
Zeyu Wang†
SIGGRAPH ), 2025
project page /
arXiv /
code
Diffusion-based asset extraction from images.
MagicScroll: Enhancing Immersive Storytelling with Controllable Scroll Image Generation
Bingyuan Wang ,
Hengyu Meng ,
Rui Cao,
Zeyu Cai ,
Lanjiong Li ,
Yue Ma ,
Qifeng Chen ,
Zeyu Wang†
VR ), 2025
project page /
paper /
code
Text-to-scroll image generation for VR.
HeadEvolver: Text to Head Avatars via Expressive and Attribute-Preserving Mesh Deformation
Duotun Wang* ,
Hengyu Meng* ,
Zeyu Cai* ,
Zhijing Shao ,
Qianxi Liu ,
Lin Wang ,
Mingming Fan ,
Xiaohang Zhan ,
Zeyu Wang†
3DV ), Oral , 2025
project page /
arXiv
Text-to-3D head avatar generation via improved mesh deformation method.
Your browser does not support the video tag.
DEGAS: Detailed Expressions on Full-Body Gaussian Avatars
Zhijing Shao ,
Duotun Wang ,
Qing-Yao Tian ,
Yao-Dong Yang ,
Hengyu Meng ,
Zeyu Cai ,
Bo Dong ,
Yu Zhang ,
Kang Zhang ,
Zeyu Wang†
3DV ), 2025
project page /
arXiv
3DGS-based 3D full body avatar reconstruction with detailed expressions.
DreamMapping: High-Fidelity Text-to-3D Generation via Variational Distribution Mapping
Zeyu Cai ,
Duotun Wang ,
Yixun Liang ,
Zhijing Shao ,
Ying-Cong Chen ,
Xiaohang Zhan ,
Zeyu Wang†
PG ), 2024
project page /
arXiv
Improved SDS based on distribution mapping.
Academic Services
Conference Reviewer
Computer Vision: CVPR, ICCV, ECCV, 3DV
Computer Graphics: SIGGRAPH, SIGGRAPH Asia, CVM, CGI