Project Page
 OmniFit
OmniFit
Multi-modal 3D Body Fitting via
Scale-agnostic Dense Landmark Prediction
ECCV 2026
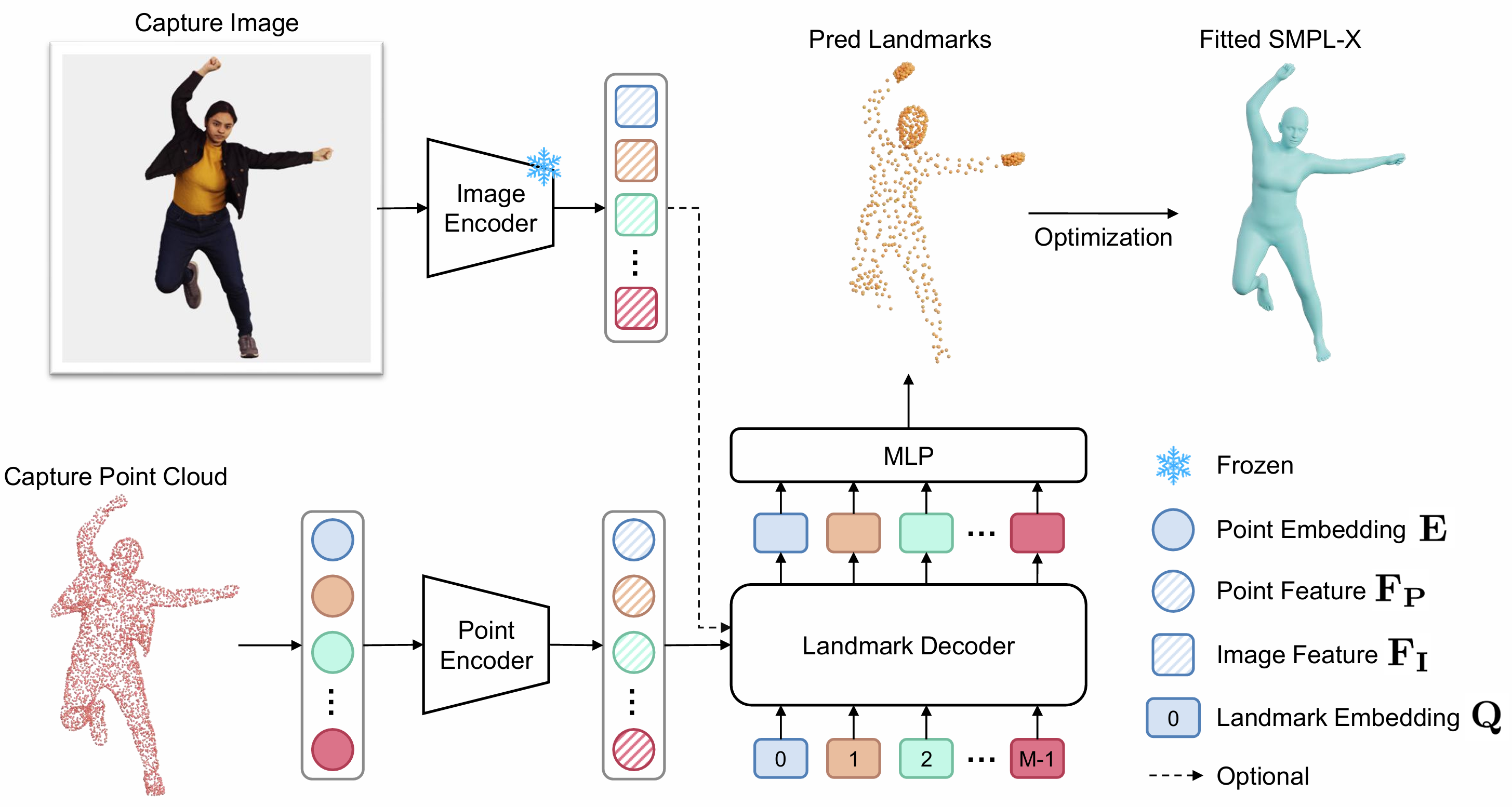
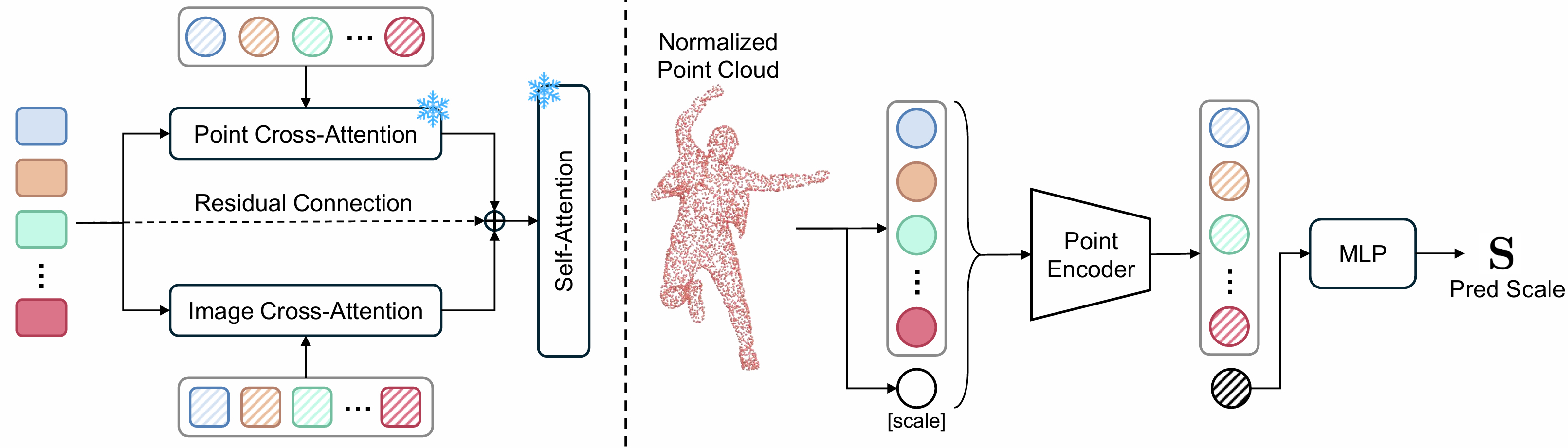
A unified 3D Human body fitting framework that robustly handles full scans, partial depth, (RGB-conditioned) point clouds, and scale-distorted AI-generated assets.
1Nanjing University
2Westlake University
3iROOTECH
4Nanjing University of Science and Technology
5The Hong Kong University of Science and Technology (Guangzhou)
† Corresponding Author